What is the difficulty?
The adage "garbage in, garbage out" highlights how important high-quality data is.

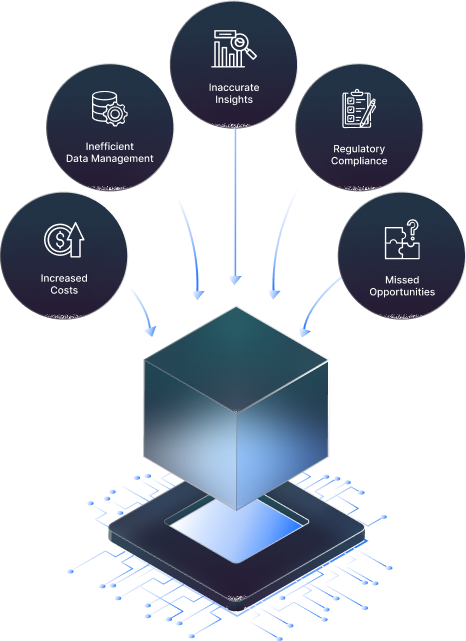
It can be challenging to manage enormous volumes of jumbled, irrelevant, and poor-quality data.
This lead to:
Inefficient data management
Large volumes of messy data can be time-consuming, costly, and challenging to store, process, and manage because they require a lot of infrastructure and resources.
Increase costs
Because organizing, processing, and maintaining messy data takes more manpower, technology, and knowledge, it can get costly.
Erroneous observations
Unstructured data can result in erroneous conclusions or insights.
Adherence to regulations
Unorganized data can make it difficult for businesses to comply with the many data privacy and security laws.
Opportunities lost
Organizations lose money and pass up possibilities when they cannot recognize trends, patterns, or opportunities that could be beneficial to them.
How do I start?
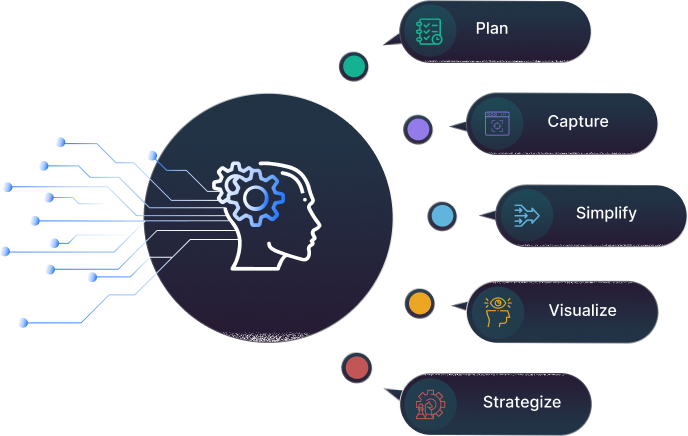
01
Make a plan in advance for everything you'll need, such as the amount of data you'll need, the data sources you'll need to connect, and—most importantly—the business objectives you have to fulfill.
02
A data warehouse's ability to collect high-quality data is essential to its success. To guarantee that the data is correct, comprehensive, and consistent, data governance policies and procedures are needed.
03
Simplify data requirements while taking data security, scalability, and redundancy into account for various demands at various stages.
04
Users can find patterns, trends, and insights with the help of effective analytics and visualization that might not be immediately apparent when examining raw data.
05
Using real data and visualization, it helps you develop your approach for better decision-making, enhanced problem-solving, and increased efficiency in a range of industries, including business, science, healthcare, and education.
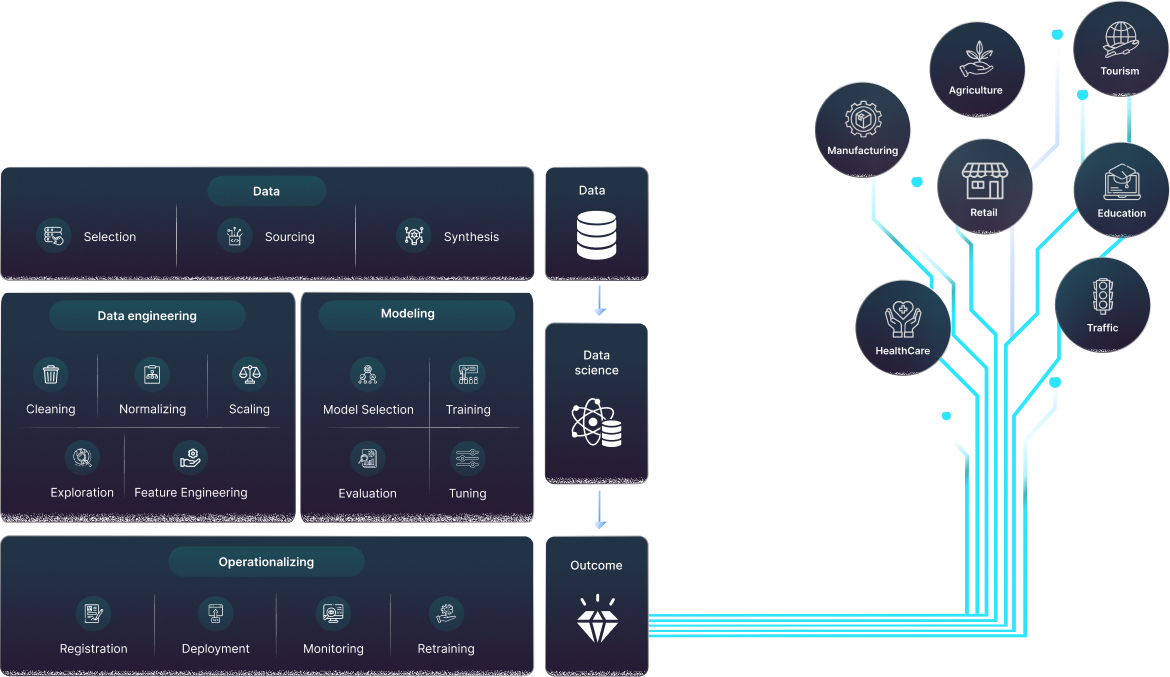
How we are going to open the black box
Data flow has its own cadence all by itself. For the appropriate audience, it gets more calming the more we adjust.

Information extraction is the process of compiling data from different sources. Many techniques, such as change data collection, batch processing, and real-time integration, are used to extract data.
The process of modifying or purifying data to guarantee accuracy, consistency, and usability is known as data transformation.
Data loading is the process of loading essential or sensitive data with encryption logic into a data lake or data warehouse.
In order to guarantee data quality, consistency, and dependability, data maintenance calls for both the building of data marts and reporting layers.
A deep dive is made possible by data mining and analysis at different stages utilizing different technologies.
Data insights provide decision-makers more freedom. Additionally, data security, data governance, and compliance are required due to the constant flow of data.
AI-powered detection of white data patches
AI can improve or automate data flow in data warehousing by performing tasks that were previously done manually.
Data sourcing and selection help the extraction process. Optical character recognition (OCR) and natural language processing (NLP) can be used to extract data from unstructured sources including emails, documents, and photos.
Additional machine learning techniques support the duties of data integration, data cleansing, and pattern recognition.
By using automated workflows and scheduling tools in a timely and effective manner, AI can help with data loading automation.
Data quality problems, abnormalities, and mistakes can be found, as well as automated data validation and reconciliation chores, by employing predictive analytics and machine learning algorithms in conjunction with a training model and ongoing tuning.
It can recognize dangers fast and take the necessary actions to abide by the registration criteria for the identification of sensitive or essential data.